
kyejin0412 님의 블로그
Week 15-1 BDA x 데이콘 공모전 - 데이터 전처리, RF 본문
이번주는 내부캠 학습주차이다.
다음주부터 최종프로젝트 주차가 시작된다. 시간이 빨리 흐를 것이라곤 예상했었는데, 그동안의 시간이 길다고 느껴졌지만 역시 지나고 보니 빨랐던 기분이다.
BDA를 수료하기 위해서는 데이콘 공모전에 반드시 참여해야한다고 해서 이번주엔 공모전을 해 볼 생각이다.
학회원 데이터를 가지고 학회를 완료할 지 아닐지 예측하는 모델을 만들고, f1 score로 평가하는 것 같다.
오늘은 머신러닝을 위한 데이터 전처리 작업을 하고 RF 모델을 한번 돌려보았다.
혼자 차분하게 진행하니 재미있었다.
0. 데이터 정보

Dataset Info.
- train.csv [파일]
- ID : 샘플별 고유 ID
- generation : BDA 기수
- school1 : 대학교
- major type : 복수전공 여부
- major1_1 : 제1전공
- major1_2 : 제2전공
- major_data : 제1전공 전공자 여부
- job : 현재 직무
- class1~4 : 수강 분반
- re_registration : 학기당 새로운 학회원을 모집할 때 재등록 여부
- contest_award : 공모전 수상 경력
- nationality : 내/외국인 여부
- inflow_route : 유입 경로
- whyBDA : BDA를 선택한 이유
- what_to_gain : BDA에서 얻고싶은 것
- hope_for_group : 조별활동 희망 여부
- previous_class_3~9 : 각 기수를 수강했을 시 분반
- major_field : 전공 분야
- desired_career_path : 희망 진로
- completed_semester : 대학교 이수학기
- project_type : 팀/개인 중 프로젝트에 참여하고 싶은 형태
- time_input : 하루에 BDA에 투입 가능한 시간
- desired_job : 희망 직무
- certificate_acquisition : 취득한 자격증
- desired_certificate : 취득을 희망하는 자격증
- desired_job_except_data : 데이터 외 희망 직무
- incumbents_level : 어느 정도 연차의 현직자를 원하는지
- incumbents_lecture : 어떤 주제의 현직자 강의를 원하는지
- incumbents_company_level : 강연 현직자가 어느정도 규모의 회사를 다니는 사람이었으면 좋겠는지
- incumbents_lecture_type : 온, 오프라인 중 원하는 현직자 강연 형태
- incumbents_lecture_scale : 원하는 현직자 강의 규모
- incumbents_lecture_scale_reason : 현직자 강의 규모 선택 이유
- interested_company : 관심있는 기업명
- expected_domain : 희망하는 도메인
- contest_participitation : 데이터 관련 대회 경험
- idea_contest : 아이디어 공모전에 대한 경험
- onedayclass_topic : 원데이 클래스 주제
- completed : (TARGET) 수료 여부(0 - 미수료 , 1 - 수료)
※ 본 대회는 기존 1회 대회와 달리, 중도 탈퇴를 예측하는 것이 아니라 학습 과정을 끝까지 완료하여 ‘수료’에 도달한 학습자를 예측하는 것을 목표로 합니다.
- test.csv [파일]
- ID : 샘플별 고유 ID
- completed 칼럼 존재하지 않음.
- 그 외 train.csv 파일과 구성 동일
- sample_submission.csv [파일] - 제출 양식
- ID : 샘플별 고유 ID
- completed : (TARGET) 수료 여부(0, 1)
1. 결측치 처리

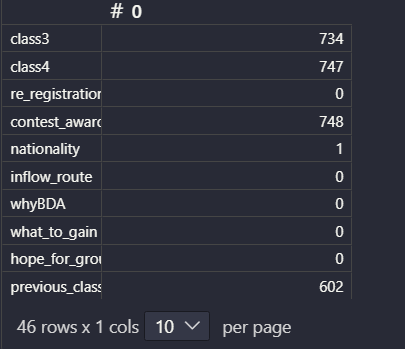



- contest_award, idea_contest : 모두 null 이므로 열 삭제
df1 = df.drop(['contest_award', 'idea_contest'], axis=1)- contest_participation : 결측치는 미참여로 간주하고 0으로 대체, 참여는 1로 라벨링
df1['contest_participation'] = df1['contest_participation'].fillna(0)
df1.loc[df1['contest_participation'] != 0, 'contest_participation'] = 1
df1['contest_participation'] = df1['contest_participation'].astype(int)- class2,3,4 결측치 -> 수강하지 않는것으로 보고 0으로 대체
# 해당 컬럼들의 NaN만 0으로 채우기
values = {'class2': 0, 'class3': 0, 'class4': 0}
df1 = df1.fillna(value=values)
- previous_class_3~8 : 결측치는 이전 기수에 수강한 분반이 없는 것으로 보고 '해당없음'으로 대체
# 변경할 컬럼과 값을 딕셔너리로 정의
fill_values = {
'previous_class_3': '해당없음',
'previous_class_4': '해당없음',
'previous_class_5': '해당없음',
'previous_class_6': '해당없음',
'previous_class_7': '해당없음',
'previous_class_8': '해당없음'
}
# fillna 적용
df1 = df1.fillna(value=fill_values)- 복수전공인데 major1_2가 결측치 -> 삭제
단일전공인데 major1_2가 있음 -> 삭제
# 해당 조건이 '아닌' 행들만 추출하여 다시 df1에 할당
df1 = df1[~((df1['major1_2'].isna()) & (df1['major type'] == '복수 전공 ( 다중전공, 이중전공 포함 )'))]
df1 = df1[~((df1['major1_2'].notna()) & ((df1['major type'] == '단일 전공') | (df1['major type'] == '단일 전공공학 (컴퓨터 공학 제외)')))]- major type 결측치 대체 : 같은 조건의 다른 행의 값으로 대체
# 조건을 변수로 저장 (가독성을 위해)
condition = (df1['major type'].isna()) & (df1['major1_1'].notna()) & (df1['major1_2'].notna())
# .loc[행 조건, 열 이름] 을 사용하여 값 변경
df1.loc[condition, 'major type'] = '복수 전공 ( 다중전공, 이중전공 포함 )'- major type이 결측치인 행 -> major1_1, major1_2, major_field 행의 결측치와 겹침 -> 삭제
# 'major type'이 NaN인 행을 삭제한 새 데이터프레임을 생성
df1 = df1.dropna(subset=['major type'])- major type이 단일전공이고 major1_2가 결측치인 경우 : 없어서 2전공이 없는 것으로 보고 '없음'으로 대체
# 1. 조건 설정 (major type이 '단일 전공' 또는 '단일 전공공학...')
condition = (df1['major type'] == '단일 전공') | (df1['major type'] == '단일 전공공학 (컴퓨터 공학 제외)')
# 2. 위 조건에 해당하면서 'major1_2'가 결측치(NaN)인 행만 선택하여 '없음' 대입
df1.loc[condition & (df1['major1_2'].isna()), 'major1_2'] = '없음'- major_field가 결측치 : 같은 조건의 다른 행의 값으로 대체, 다른 하나는 삭제
# 1. 조건 정의 (가독성을 위해 변수로 지정)
condition = (df1['major1_1'] == '경제통상학') & \
(df1['major1_2'] == 'IT(컴퓨터 공학 포함)') & \
(df1['school1'] == 1)
# 2. .loc[조건, '수정할컬럼명']을 사용하여 값 변경
df1.loc[condition, 'major_field'] = 'IT (컴퓨터 공학 포함), 경제통상학'
# 'major_field' 열이 NaN(결측치)인 행을 삭제
df1 = df1.dropna(subset=['major_field'])- completed_semester : 결측치 삭제 (양이 적고 추정 불가)
# 'completed_semester' 열이 NaN(결측치)인 행을 삭제
df1 = df1.dropna(subset=['completed_semester'])- nationality 결측치 대체
df1['nationality'] = df1['nationality'].fillna('내국인')
2. 이상치 처리
- major_data : 제1전공이 전공자인지 여부. 관련 전공이 아니면 False 처리
# 1. '관련 전공'으로 분류할 항목 리스트 정의 (직접 연관 전공)
da_majors = ['IT(컴퓨터 공학 포함)', '자연과학', '경제통상학']
# 2. major1_1의 값이 위 리스트에 있으면 True, 없으면 False 할당
df1['major_data'] = df1['major1_1'].isin(da_majors)- completed_semester : 이수한 학기가 20241개인 데이터 -> 이상치 삭제
df3[df3['completed_semester'] == 20241]
3. 머신러닝에 필요없는 컬럼 제거
df2 = df2.drop(['ID', 'generation','incumbents_lecture_scale_reason',
'interested_company','expected_domain','onedayclass_topic'], axis=1)
# 나중에 추가 삭제함
df3 = df3.drop(['nationality','inflow_route','whyBDA','what_to_gain','desired_job','certificate_acquisition','desired_certificate',
'desired_job_except_data','incumbents_level','incumbents_lecture','incumbents_company_level','incumbents_lecture_type',
'incumbents_lecture_scale','contest_participation'], axis=1)
4. 랜덤포레스트, XGB용 데이터 인코딩 (원핫 인코딩 + 라벨 인코딩)
df3 = pd.get_dummies(df3, columns=['major type'], dtype=int)
df3 = df3.drop(['major type_단일 전공'], axis=1)
# '제1전공', '제2전공' 컬럼을 원-핫 인코딩 (기존 컬럼은 사라지고 전공별 컬럼 각각 11개가 생깁니다)
df3 = pd.get_dummies(df3, columns=['major1_1', 'major1_2'], dtype=int)
# 데이터 전공자여부 0,1로 구분
df3['major_data'] = df3['major_data'].astype(int)
# 현재 직업 인코딩
df3 = pd.get_dummies(df3, columns=['job'], dtype=int)
# class2-4 정수화
# 반드시 대괄호를 두 번 [[ ]] 써야 함 (여러 컬럼 선택 시)
cols = ['class2', 'class3', 'class4']
df3[cols] = df3[cols].astype(int)
df3 = pd.get_dummies(df3, columns=['class1', 'class2', 'class3', 'class4'], dtype=int)
# 그 외에 대소관계가 명확하지 않은 컬럼들
df3 = pd.get_dummies(df3, columns=['re_registration', 'hope_for_group', 'previous_class_3', 'previous_class_4',
'previous_class_5','previous_class_6','previous_class_7','previous_class_8',
'desired_career_path','project_type'], dtype=int)
# 전공을 나타내는 컬럼이 있으므로 major_field는 삭제
df3 = df3.drop(['major_field'], axis=1)
# 이수한 학기는 대소관계이므로 그대로 남김. 정수화만 진행
df3['completed_semester'] = df3['completed_semester'].astype(int)
# time_input : 투자한 시간은 대소관계가 유의미하므로 그대로 남김.
5. csv 파일로 저장
df3.to_csv('preprosseing.csv')
6. 머신러닝 - RF
종속변수가 범주형이고, 답이 있으므로 분류 지도학습을 진행한다.
대소관계로 오인될 수 있는 컬럼들은 대부분 원핫 인코딩을 진행하여 해소 했지만, 'school1' 컬럼은 값이 많아 그대로 놔두었다.
대소관계에 크게 영향받지 않는 트리기반 모델(랜덤포레스트, XGB)을 선택하여 안전한 성능을 보장하고자 한다.
오늘은 랜덤포레스트를 진행해보았다.
- 라이브러리 import
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, f1_score, precision_recall_curve
from sklearn.model_selection import train_test_split
- 데이터 불러오기
# 데이터 불러오기
df = pd.read_csv("preprocessing.csv")
- 머신러닝에 사용할 컬럼/타깃 분리
# 머신러닝에 사용할 컬럼/타깃 분리
x = df.drop(columns=["completed"])
y = df["completed"]
- train, test set 분리
# train / test 분리
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
- RF 적용
# RandomForest 적용
rf = RandomForestClassifier(
n_estimators=200, # 트리 개수
max_depth=None, # 깊이는 제한하지 않고 알아서
random_state=42,
)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
# RandomForest 적용
# 혼동행렬
# 예측과 실제데이터에 대한 결과표
# confusion_matrix로 구현
# ㅁㅁ >>> TN(실제로NO, 예측도 NO -> NO 를 맞춤), FP(실제로는 NO, 예측은 YES -> 잘못 예측)
# ㅁㅁ >>> FN(실제로 YES, 예측은 NO -> 잘못 맞춤), TP(실제로 YES, 예측도 YES -> YES 를 맞춤)
confusion_matrix(y_test, y_pred_rf)
# '완료(1)'일 확률만 추출
y_scores = rf.predict_proba(X_test)[:, 1]
# 2. 임계값에 따른 Precision, Recall, Thresholds 계산
precisions, recalls, thresholds = precision_recall_curve(y_test, y_scores)
# 3. F1-score가 최대가 되는 지점의 임계값 찾기
# f1 = 2 * (precision * recall) / (precision + recall)
f1_scores = 2 * (precisions * recalls) / (precisions + recalls)
best_threshold = thresholds[np.argmax(f1_scores)]
print(f'Best Threshold: {best_threshold:.4f}')
print(f'Best F1-Score: {np.max(f1_scores):.4f}')
# 4. 최적 임계값을 적용하여 최종 예측값 생성
final_preds = (y_scores >= best_threshold).astype(int)
# 최종 성능 확인
print(f"Final F1-score with optimized threshold: {f1_score(y_test, final_preds):.4f}")
- 결과 확인
# RandomForest 적용
# 결과 확인
print(classification_report(y_test, y_pred_rf))'BDA' 카테고리의 다른 글
| [BDAI] 원데이 클래스 - SQL 기반 KPI 설정 (0) | 2026.03.29 |
|---|---|
| Week 18-7 BDA x 데이콘 최종과제 공모전 후기 (0) | 2026.02.23 |
| 2025 한국빅데이터학회 추계학술행사 - 빅데이터 기반의 Agent AI (0) | 2025.11.24 |
| [BDA] 1주차 - BDA를 선택하게 된 이유, 기대되는 점 (0) | 2025.09.22 |